”爬虫 python scrapy“ 的搜索结果
pythonscrapy爬虫实例Python爬虫Scrapy实例
py爬虫Python爬虫Scrapy培训源码提取方式是百度网盘分享地址
1 爬虫示例 要实现爬虫功能,只要执行四个步骤: 定义spider 类 确定 spider 的名称(name) 获取初始化请求(start_request) 解析数据 parse() 1.1 示例1 重写 start_request() 方法 示例1:重写 start_request() ...
精通Python爬虫框架Scrapy.pdf
Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。 小刮刮是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者...
Scrapy是一个高层次的Python爬虫框架,用于快速、高效地爬取网站数据。它提供了一套基于Twisted的异步网络库,可以更好地处理并发请求和响应。Scrapy框架具有很强的可扩展性,可以通过编写定制化的扩展实现各种功能...
知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到...

Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,...
注意事项:scrapy和twisted存在兼容性问题,如果安装twisted版本过高,运行scrapy startproject project_name的时候会提示报错,安装twisted==13.1.0即可。

我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。...
主要给大家介绍了利用python爬虫框架scrapy爬取京东商城的相关资料,文中给出了详细的代码介绍供大家参考学习,并在文末给出了完整的代码,需要的朋友们可以参考学习,下面来一起看看吧。

make;启动:/root/redis-3.2.11/src/...小编创建了一个Python学习交流QQ群:857662006寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!‘’’1、安装wheel2、安装lxml3、安装pyopenssl。
python scrapy 企业级分布式爬虫开发架构模板 python scrapy 开发企业级分布式爬虫开发架构,使用该架构可快速搭建分布式爬虫环境。 相关技术 使用scrapy_redis进行分布式爬虫操作。 使用mongodb存储数据 开发环境...
python爬虫,Scrapy抓手机App数据并存入MongoDB(今日头条)python爬虫,Scrapy抓手机App数据并存入MongoDB(今日头条)python爬虫,Scrapy抓手机App数据并存入MongoDB(今日头条)python爬虫,Scrapy抓手机App数据...
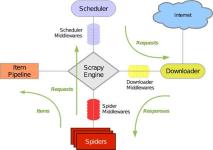
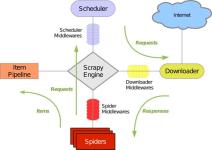
scrapy的中间件理论上有三种(Schduler Middleware,Spider Middleware,Downloader Middleware),在应用上一般有以下两种。当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,...
精通python爬虫框架scrapy源码修改原始码可编辑python3版本 本书涵盖了期待已久的Scrapy v 1.0,它使您能够以极少的努力从几乎任何来源中提取有用的数据。 首先说明Scrapy框架的基础知识,然后详细说明如何从任何...
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。
python scrapy 爬虫基础 分布式爬虫 scrapy python scrapy 爬虫基础 分布式爬虫 scrapy

开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源python网络爬虫框架Scrapy.pdf开源...
scrapy提供一个工具来生成项目,生成的项目中预置了一些文件,用户需要在这些文件中添加自己的代码。 打开命令行,执行:scrapy startproject tutorial,生成的项目类似下面的结构 tutorial/ scrapy.cfg ...
1 scrapy全站爬取 1.1 全站爬取简介 CrawlSpider:全站数据爬虫的方式,它是一个类,属于Spider的子类 如果不使用CrawlSpider,那么就相当于基于...切换到爬虫工程中后,创建爬虫文件:scrapy genspider -t crawl xxx

主要介绍了python爬虫库scrapy简单使用实例详解,需要的朋友可以参考下
推荐文章
- 用好ASP.NET 2.0的URL映射-程序员宅基地
- C语言等级考试是把题目删了,历年全国计算机的等级考试二级C语言上机考试地训练题目库及答案详解(72页)-原创力文档...-程序员宅基地
- Microsoft Office显示正在更新无法打开的问题_正在更新microsoft 365和office-程序员宅基地
- 非常好的Ansible入门教程(超简单)-程序员宅基地
- 【Gradle-8】Gradle插件开发指南-程序员宅基地
- 使用PL/SQL Developer软件解锁_plsqldev表格锁怎么打开-程序员宅基地
- 【Windows Server 2019】Web服务 IIS 配置与管理——配置 IIS 进阶版 Ⅳ_iis默认路径-程序员宅基地
- 网络中的各层协议_发送消息时各层协议-程序员宅基地
- UCRT: VC 2015 Universal CRT, by Microsoft_vc15rt-程序员宅基地
- 关于EntityFramework 7 开发学习_entiry framework 7 书籍-程序员宅基地